Algoritmos para juegos | Tema 1: Algoritmos sobre grafos Por Alejandro Vargas Lugo Obra de creación propia bajo licencia Creative Commons BY-NC-SA 4.0 Internacional https://creativecommons.org/licenses/by-nc-sa/4.0/deed.es
Introducción¿Qué es un grafo?Tipos de grafosRepresentaciones de grafosLista de adyacenciasMatriz de adyacenciasInicialización de grafos en ejerciciosPara crear una lista de adyacenciasPara crear una matriz de adyacenciasAlgoritmos de recorridoRecorrido en profundidad (DFS)Recorrido en anchura (BFS)Ordenación topológicaAlgoritmo de Kahn
Introducción
¿Qué es un grafo?
En el ámbito de la informática, un grafo es una estructura de datos que agrupa varios objetos, denominados vértices (o nodos), los cuales se unen mediante enlaces llamados aristas (o caminos). Los grafos nos permiten representar una gran variedad de situaciones en las cuales hay varias entidades relacionadas entre sí, y donde se precisa aplicar algoritmos que ayuden a resolver problemas asociados a cómo se relacionan estos objetos.
Veamos un ejemplo. La imagen de la parte inferior podría parecer un simple fragmento de un plano de metro…

…Pero si quitamos las etiquetas de las estaciones, la ilusión desaparece, y el resultado es un grafo, donde los vértices son las estaciones: las entidades relacionadas entre sí mediante las líneas de metro, que son las aristas.
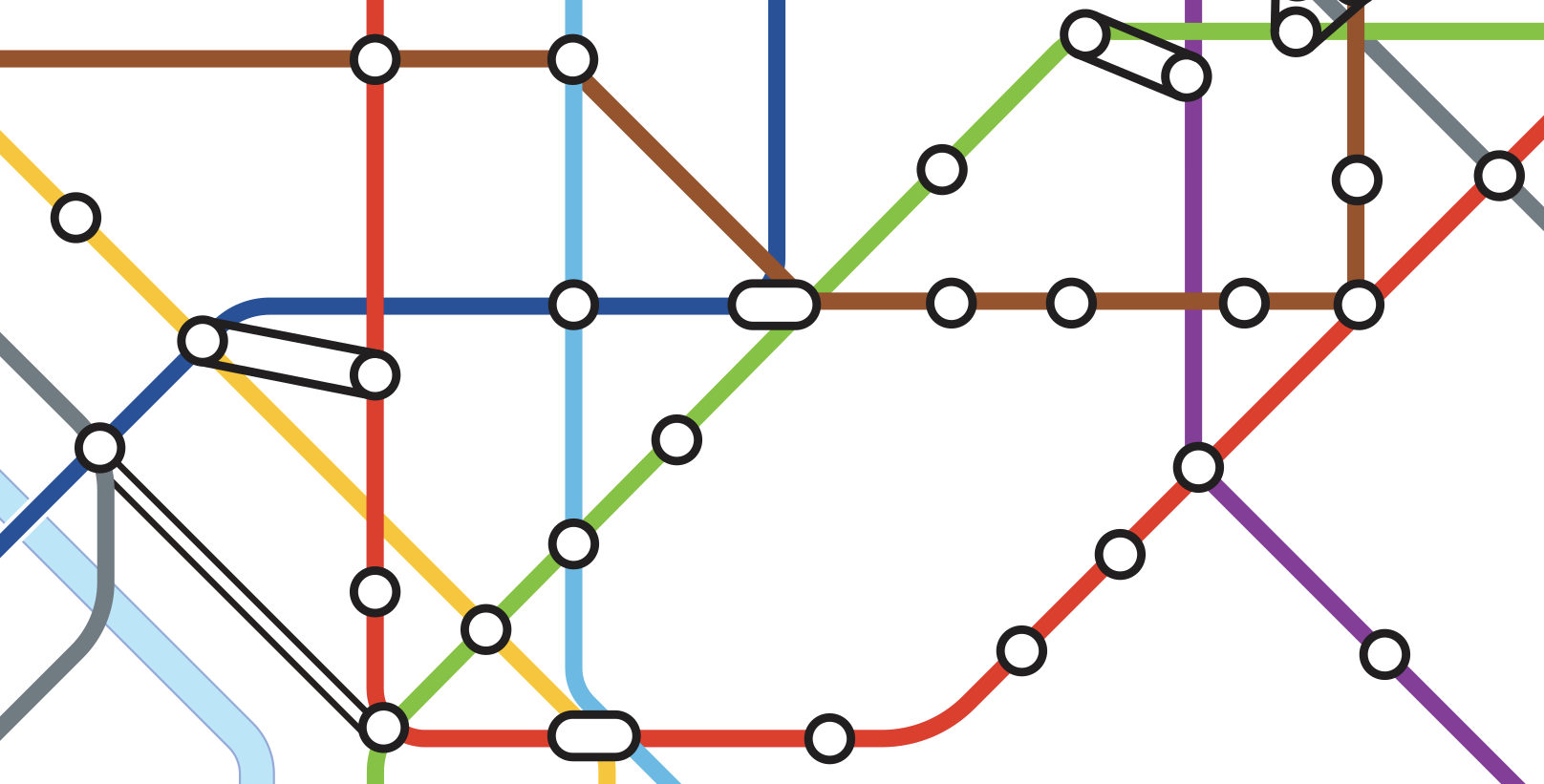
Los problemas que podríamos querer resolver, por ejemplo, incluyen:
Calcular la ruta más corta para llegar desde una estación hasta otra.
Calcular el mínimo número de transbordos que debo realizar.
Determinar si tendré que pasar por una zona tarifaria (y por tanto pagar más).
Saber cómo de lejos podré ir si tengo solo 2 euros.
Nos estamos adelantando un poco, pero algunos de estos problemas los resolveremos en este mismo tema, mientras que otros los dejaremos para el futuro (algoritmos voraces sobre grafos).
Tipos de grafos
Los grafos se pueden clasificar de varias maneras según la forma en la que están conectados sus vértices.
La clasificación más importante es la de grafos dirigidos o no dirigidos. En el primer caso, las aristas entre vértices son unidireccionales, es decir, sólo permiten el recorrido en un único sentido. En cambio, en los no dirigidos las aristas son bidireccionales, y permiten el recorrido en un sentido o en otro.
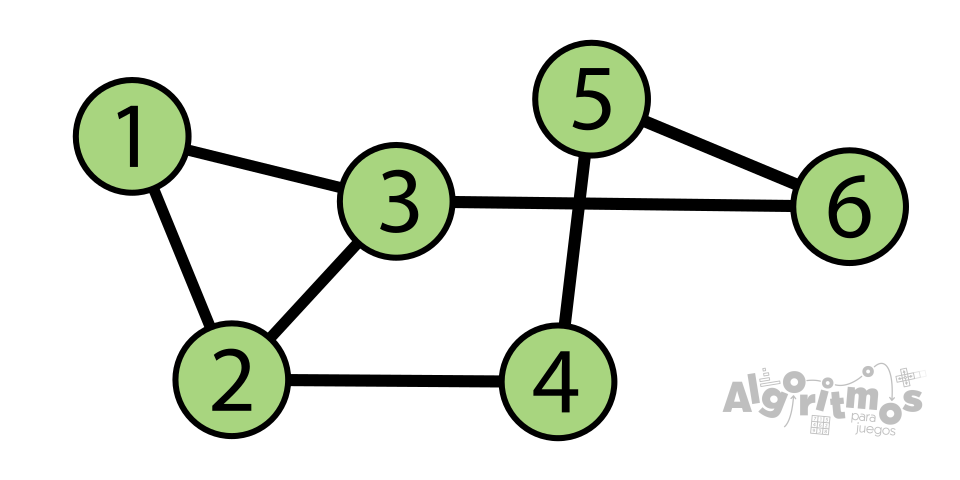
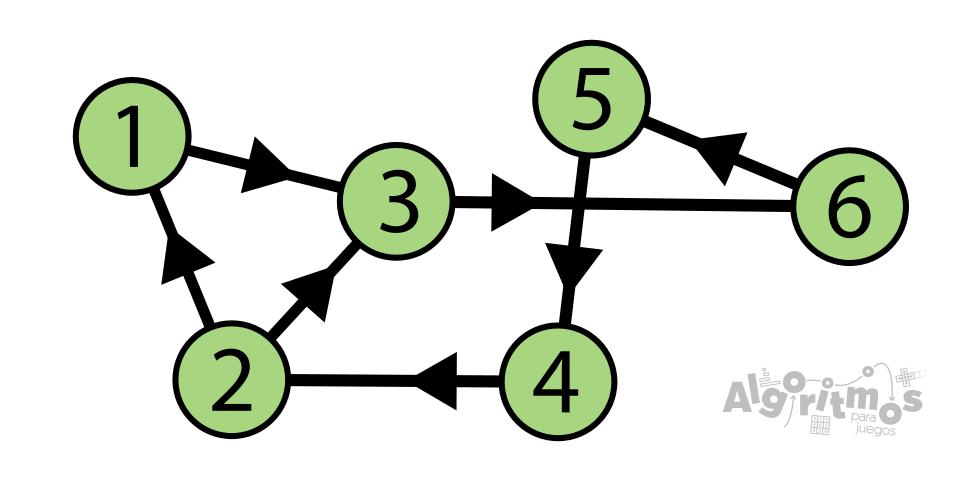
Fíjate en las dos imágenes de la parte superior. Supongamos que partimos desde el vértice 1. En el caso de la izquierda (no dirigido) para llegar al nodo 4 es evidente que el camino más corto es 1-2-4. Sin embargo, en el caso de la derecha (dirigido), el camino 1-2 sólo permite el recorrido en un sentido (del 2 al 1) por lo que, para llegar al mismo nodo 4, tendremos que tomar el recorrido 1-3-6-5-4.
Otra distinción importante dentro de los grafos no dirigidos es la de grafo conexo y no conexo. En un grafo conexo, cualquier par de vértices deben estar conectados por al menos un recorrido. En otras palabras, desde cualquier nodo se debe poder llegar hasta cualquier otro nodo. Los grafos no cumplen esta condición si hay al menos un vértice “aislado” del resto, en cuyo caso son no conexos.
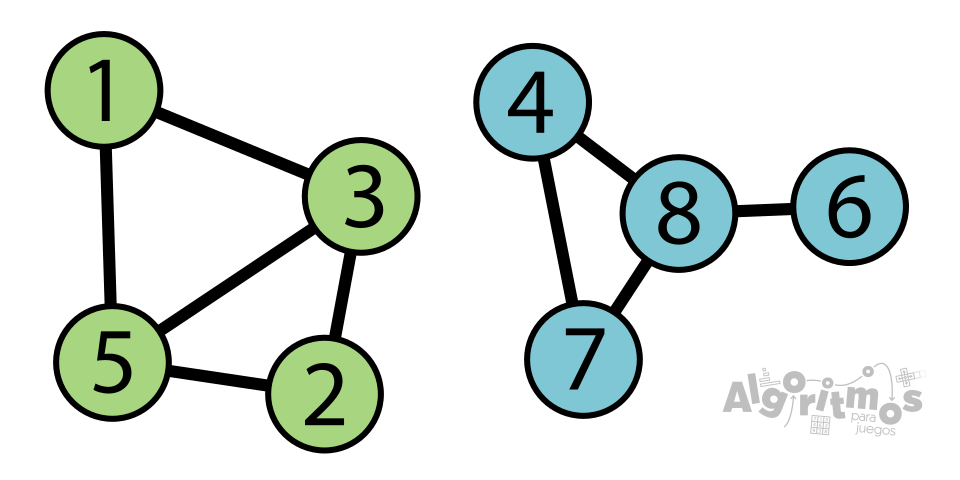
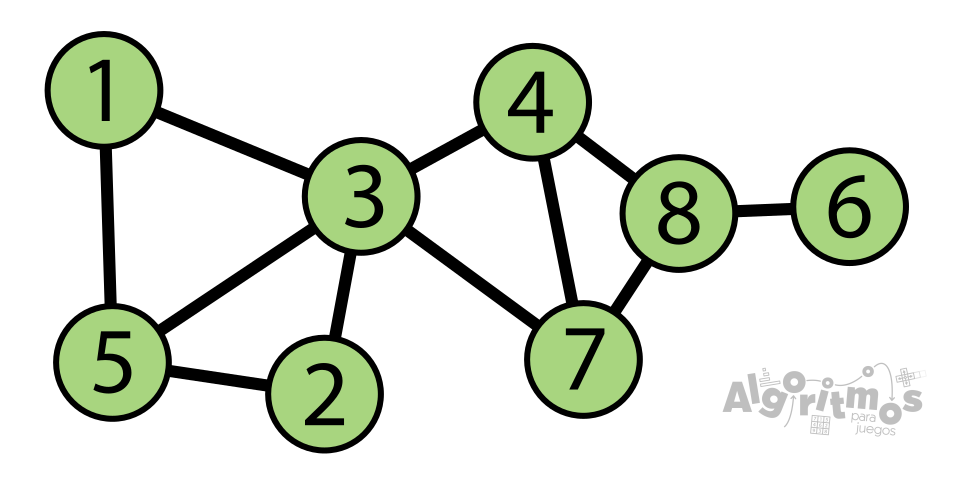
Como se puede observar en este par de imágenes, el grafo de la izquierda es no conexo, y cuenta con dos componentes aislados entre sí (marcados aquí con dos colores distintos). El grafo de la derecha es conexo.
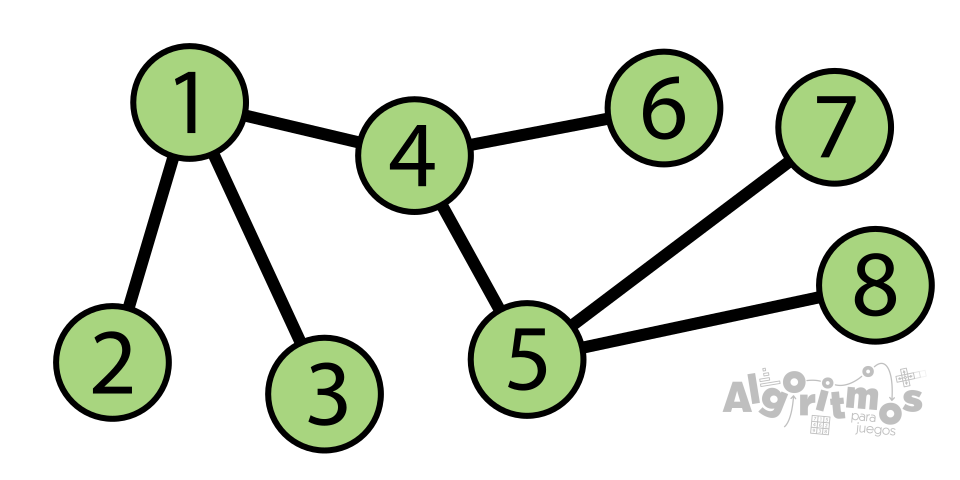
Un concepto muy importante dentro de los grafos es el de ciclo. Un ciclo es un camino cerrado en el que no se repiten vértices. Es decir, que comienza y termina en el mismo vértice, sin repetir vértices ni aristas intermedias (sin “volver hacia atrás”). Un grafo puede contener varios ciclos, pero aquel que no posee ninguno se denomina árbol (ver imagen inferior).
Por último, hablaremos del concepto de grafo ponderado. En un grafo de este tipo, cada arista lleva asociado un peso (o valor). Estos pesos pueden representar distancias, costes, tiempos, entre otros, según el tipo de problema con el que se está trabajando. Por ejemplo, en una red de caminos de senderismo, cada arista indicaría la distancia entre los dos vértices conectados. En una red de metro, cada arista podría indicar el tiempo que tarda el tren en ir de un vértice a otro.
Representaciones de grafos
Existen dos formas principales de representar grafos: mediante lista de adyacencias o matriz de adyacencias.
Lista de adyacencias
En una lista de adyacencias, para cada vértice, se guarda una lista de vértices a los que está conectado. Veamos un ejemplo:
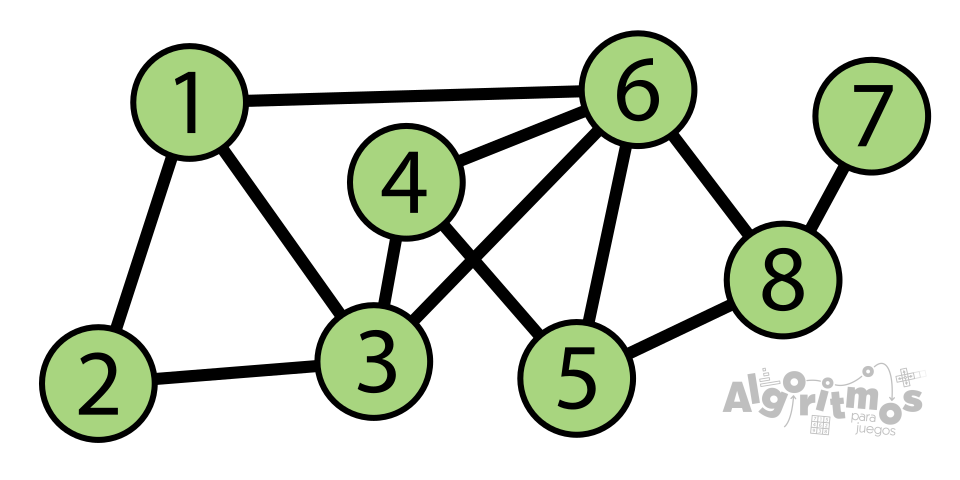
Si fuéramos vértice a vértice, por orden lexicográfico (empezando desde el 1) enumerando los vértices a los que está conectado, nos quedaría algo así:
Vértice 1 está conectado al 2, 3 y 6.
Vértice 2 está conectado al 1 y 3.
Vértice 3 está conectado al 1, 2, 4 y 6.
[…]
Vértice 7 está conectado a 8.
Vértice 8 está conectado a 5, 6 y 7.
Representado usando una “lista de listas” en Python, nos quedaría lo siguiente:
[[2, 3, 6],[1, 3],[1, 2, 4, 6],[3, 5, 6],[4, 6, 8],[1, 3, 4, 5, 8],[8],[5, 6, 7]]No es necesario agregar el propio vértice al que corresponde cada entrada, se intuye por el índice dentro de la lista principal (la cuarta lista corresponde al cuarto vértice). ¡PERO MUCHO CUIDADO! Recuerda que las listas empiezan con índice cero, por lo que, si tu grafo empieza en 1, deberás compensar por esa diferencia. En la mayoría de ejercicios el primer nodo convenientemente tendrá índice 0, así que no deberás preocuparte, pero es un factor que igualmente debes tener en cuenta.
En un grafo no dirigido, el número de entradas será igual al doble del número de aristas (tiene sentido: una entrada para 1-2 y otra para 2-1, aunque sean la misma arista). En los dirigidos, evidentemente, el número de entradas será igual al número de aristas.
El número de listas crece de forma lineal con respecto al número de vértices (7 vértices = lista de 7 listas) por lo que esta estructura es ideal para grafos dispersos (muchos vértices con pocas aristas, p. ej. una red de estaciones de metro). Por otra parte, determinar si existe una arista entre dos vértices tiene complejidad O(N), ya que es necesario recorrer la lista correspondiente a ese índice hasta encontrar (o no) el otro vértice.
Matriz de adyacencias
Una matriz de adyacencias consiste en una matriz cuadrada de tamaño N x N, siendo N el número de vértices, en la que cada posición (x, y) indica si existe una arista entre los vértices x e y. Si existe, dicha posición tendrá un uno. Si no, tendrá un cero.
Usando el mismo grafo de antes, veamos cómo quedaría dicha matriz:
xxxxxxxxxx[[0, 1, 1, 0, 0, 1, 0, 0],[1, 0, 1, 0, 0, 0, 0, 0],[1, 1, 0, 1, 0, 1, 0, 0],[0, 0, 1, 0, 1, 1, 0, 0],[0, 0, 0, 1, 0, 1, 0, 1],[1, 0, 1, 1, 1, 0, 0, 1],[0, 0, 0, 0, 0, 0, 0, 1],[0, 0, 0, 0, 1, 1, 1, 0]]El tamaño de la matriz de adyacencias crece cuadráticamente con respecto al número de vértices (Nº de entradas = |V|2), así que funciona mejor con grafos densos (pocos vértices, muchas aristas, p. ej. una red de contactos o amigos de una empresa). Con respecto al problema de determinar si hay arista entre un par de vértices, en este caso la complejidad es de O(1), ya que sólo hay que acceder a las coordenadas correspondientes y ver si el valor es 0 o distinto de cero.
Inicialización de grafos en ejercicios
La matriz de adyacencias facilita además la representación de grafos ponderados, en las que cada arista tiene un peso/coste determinado. En este caso donde exista una arista, en vez de usarse un 1 exclusivamente se introduce directamente el peso de la propia arista.
En la mayoría de problemas de grafos no se proporcionará directamente la lista o matriz de adyacencias, sino que nos pasarán el número de vértices y aristas del grafo en una primera línea, seguido de una lista de vértices, cada una en una línea, y será nuestro trabajo convertir esa lista en una de las dos estructuras de datos que hemos visto. Veamos cómo se hace en cada caso:
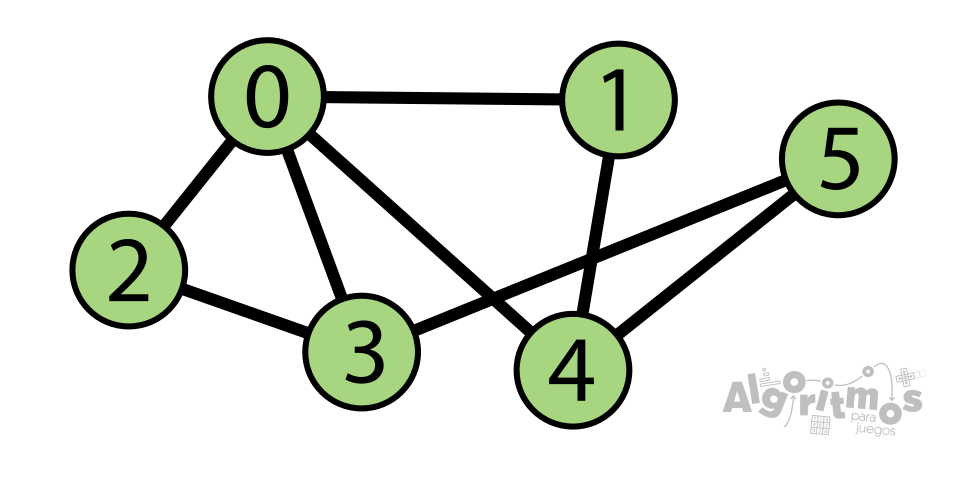
Tomemos como ejemplo la siguiente entrada sin procesar (similar a la que encontrarás en los ejercicios). La primera fila contiene el número de vértices (6) y de aristas (8), seguido de ocho filas, cada una correspondiente a una arista:
xxxxxxxxxx6 80 10 20 30 41 42 33 54 5Esta entrada corresponde al siguiente grafo:
Para crear una lista de adyacencias
Asignamos los dos primeros valores a dos variables, que llamaremos [v] (vértices) y [e] (aristas, edges en inglés).
Inicializamos el grafo [g] como una lista de listas vacías (sabiendo que habrá [v] listas en total: en este caso seis).
Creamos un bucle for que itere un total de [e] veces (para leer cada una de las líneas, cada una correspondiente a una arista)
En cada iteración realizamos dos acciones:
Leemos los dos valores y los asignamos a dos variables que llamaremos [a] y [b]. Estos son los dos vértices conectados por la arista actual.
LO MÁS IMPORTANTE: A la lista con índice [a] agregamos el vértice [b], y si el grafo es no dirigido, lo propio en viceversa (a la lista con índice [b], agregamos [a]).
Así quedaría en código:
xxxxxxxxxxv, e = map(int, input().split())g = [[] for _ in range(v)]for _ in range(e): a, b = map(int, input().split()) g[a].append(b) g[b].append(a) # SOLO si es NO dirigidoPara crear una matriz de adyacencias
Asignamos los dos primeros valores a dos variables, que llamaremos [v] (vértices) y [e] (aristas), edges en inglés).
Inicializamos el grafo [g] como una matriz de tamaño [v] * [v] llena de ceros.
Creamos un bucle for que itere un total de [e] veces (para leer cada una de las líneas, cada una correspondiente a una arista)
En cada iteración realizamos dos acciones:
Leemos los dos valores y los asignamos a dos variables que llamaremos [a] y [b]. Estos son los dos vértices conectados por la arista actual.
Accedemos a las coordenadas [a] [b] de la matriz y escribimos un 1 en él. Si el grafo es no dirigido, también se accede a las coordenadas [b] [a]
xxxxxxxxxxv, e = map(int, input().split())g = [[0 for _ in range(v)] for _ in range(v)]for _ in range(e): a, b = map(int, input().split()) g[a][b] = 1 g[b][a] = 1 # SOLO si es NO dirigidoAlgoritmos de recorrido
Los algoritmos de recorrido atraviesan todos los nodos de un grafo según un criterio especifico. En este tema estudiaremos el recorrido en profundidad (DFS, depth-first search) y el recorrido en anchura (BFS, breadth-first search)
Recorrido en profundidad (DFS)
En el recorrido en profundidad, partiendo de un vértice inicial (que, en nuestro caso, será por lo general el nodo con índice cero o uno, excepto cuando el enunciado indique lo contrario) se explora un camino avanzando tan lejos como sea posible hasta alcanzar un punto muerto (un punto sin vértices adyacentes no visitados), en cuyo caso se retrocede para probar otros caminos aún sin explorar. El algoritmo finaliza una vez se han visitado todos los nodos alcanzables desde el vértice inicial. En caso de haber varios componentes no conexos, el algoritmo se ejecuta de nuevo para cada uno de ellos.
¿Mucho texto? No te preocupes, echemos un vistazo a la implementación en código Python:
x# Función auxiliar recursivadef dfs_rec(node, graph, visited): visited.add(node) for u in graph[node]: if u not in visited: dfs_rec(u, graph, visited)
# Función principaldef dfs(g): visited = set() for v in range(0, len(g)): if v not in visited: dfs_rec(v, g, visited)Como puedes ver, el código consta de dos funciones: dfs, desde donde comienza el algoritmo; y dfs_rec, la función auxiliar recursiva que va explorando el grafo.
dfsrecibe nuestro grafo completo. En este caso, en formato de lista de adyacencias.Al empezar, inicializaremos un conjunto de nodos visitados,
visited, inicialmente vacío. A medida que vayamos recorriendo el grafo, iremos añadiendo los nodos que hayamos visitado, y de esta manera, evitaremos hacer recorridos duplicados.Bucle principal: aquí iteramos sobre cada uno de los nodos del grafo:
range(0, len(g))y en caso de que no aparezcan en el conjunto de visitados, los visitamos y comenzamos la iteración recursiva desde ese nodo. ¿Qué significa esto? Si el grafo es no conexo, tendrá que haber como mínimo dos nodos desde donde tendremos que entrar al grafo para poder recorrerlo entero. Por ejemplo, si tomamos el grafo no conexo de antes:
Esta sería la secuencia de visitas que se llevaría a cabo:

Función recursiva: aquí es donde se desarrolla buena parte de la acción. Primero agregamos el nodo actual a la lista de nodos visitados. Después, miramos cada uno de los vecinos del nodo:
graph[node], dondenodees nuestro nodo actual. Cuando hallemos uno que no haya sido visitado, llamaremos de nuevo a esta función recursiva partiendo desde ese nodo.Llegará un momento en el que no podamos seguir visitando nodos. En ese caso, la propia recursividad nos "llevará para atrás" y podremos seguir explorando los vecinos que se nos quedaron pendientes.
Applet interactivo: ¿Aún tienes dudas? ¿Quieres probar con tus propios grafos? ¡Prueba el applet interactivo del recorrido en profundidad!
Recorrido en anchura (BFS)
En el recorrido en anchura, partiendo de un vértice inicial (que, en nuestro caso, será por lo general el nodo con índice cero o uno, excepto cuando el enunciado indique lo contrario) se exploran primero todos los vértices adyacentes no visitados al nodo actual. Posteriormente, se continúa con los nodos descubiertos siguiendo el mismo criterio, avanzando nivel por nivel en el grafo. Para gestionar el orden de exploración normalmente se utiliza una cola. El algoritmo finaliza una vez se han visitado todos los nodos alcanzables desde el vértice inicial. En caso de haber varios componentes no conexos, el proceso se repite para cada uno de ellos.
Igual que antes, echemos un vistazo a la implementación en código Python para entenderlo mejor:
xxxxxxxxxxfrom collections import deque
# Función auxiliardef bfs_aux(node, g, visited): queue = deque() visited.add(node) queue.append(node) while queue: v = queue.popleft() for adj in g[v]: if adj not in visited: visited.add(adj) queue.append(adj)
# Función principaldef bfs(g): n = len(g) visited = set() for v in range(0, n): if v not in visited: bfs_aux(v, g, visited)Hay que destacar dos grandes diferencias con el DFS. Primero, como puedes observar, aunque seguimos separando el algoritmo en dos funciones (bfs y bfs_aux), este algoritmo no es recursivo. En su lugar (y esta es la segunda gran diferencia), haremos uso de un deque (double-ended queue; cola doblemente terminada). Esta estructura de datos nos permite introducir los nodos en un extremo de la cola e irlos sacando por el extremo opuesto de forma eficiente, implementando una estrategia FIFO (first-in first-out).

La función principal bfs funciona exactamente igual que su equivalente en DFS. Incializamos un conjunto de nodos visitados, iteramos sobre cada uno de los nodos del grafo y comenzamos el recorrido en anchura desde el primero que no esté visitado. Igual que en el DFS, si el nodo es no conexo, habrá que entrar desde al menos dos nodos para poder recorrer el grafo entero.
La función auxiliar es donde cambia la cosa:
Primero inicializamos un deque, al que llamaremos
queue(cola). Esta estructura de datos forma parte del módulocollections, así que debemos importarla primero confrom collections import deque(fuera de la función).Añadimos el nodo actual al conjunto de nodos visitados y a la cola.
El punto clave: mientras siga habiendo elementos en la cola, vamos a ir retirándolas, y añadiendo sus vecinos que no hayan sido aún visitados a la cola, para recorrerlos posteriormente. De esta manera, cuando ya no queden nodos en la cola es porque ya habremos acabado de recorrer el grafo (o una de sus componentes conexas)
Applet interactivo: ¿Aún tienes dudas? ¿Quieres probar con tus propios grafos? ¡Prueba el applet interactivo del recorrido en anchura!
Ordenación topológica
Los algoritmos de ordenación topológica (toposort) tienen como propósito obtener una ordenación lineal de todos los nodos de un grafo dirigido acíclico (DAG), de manera que, para cada arista dirigida u -> v, el nodo U aparezca antes que el V en la secuencia resultante. Es decir, que cada nodo esté precedido por aquellos a los que apunta.
Este tipo de ordenación respeta las relaciones de precedencia y dependencia marcada por las aristas dirigidas entre los nodos. Sólo es posible realizar la ordenación si el grafo no contiene ciclos dirigidos, pues eso resultaría en una dependencia circular irresoluble.
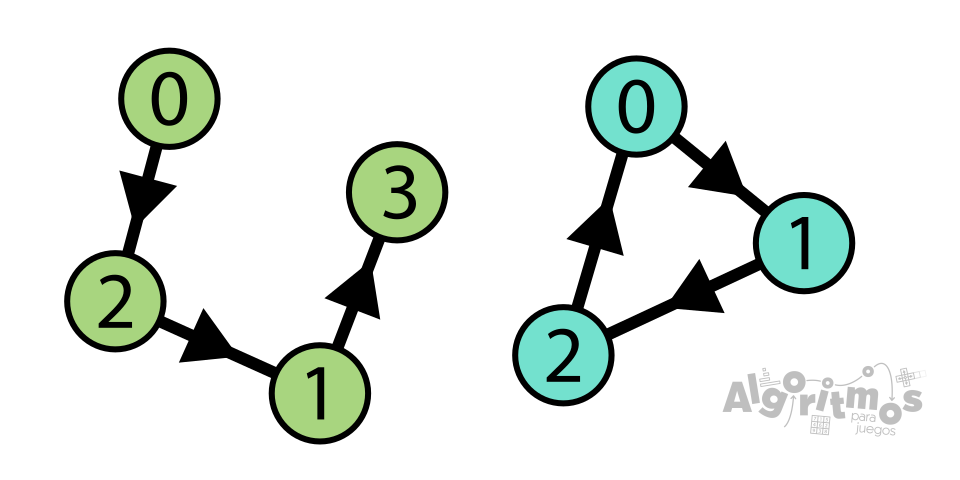
En este ejemplo, el grafo verde tiene una ordenación clarísima: 0 - 2 - 1 - 3. SIn embargo, el grafo azul es imposible de ordenar, no hay forma de determinar qué nodo va "primero".
También hay que tener en cuenta un aspecto clave de las ordenaciones topológicas, y es que, según el grafo, pueden existir varias soluciones. Fíjate en el siguiente grafo, por ejemplo:
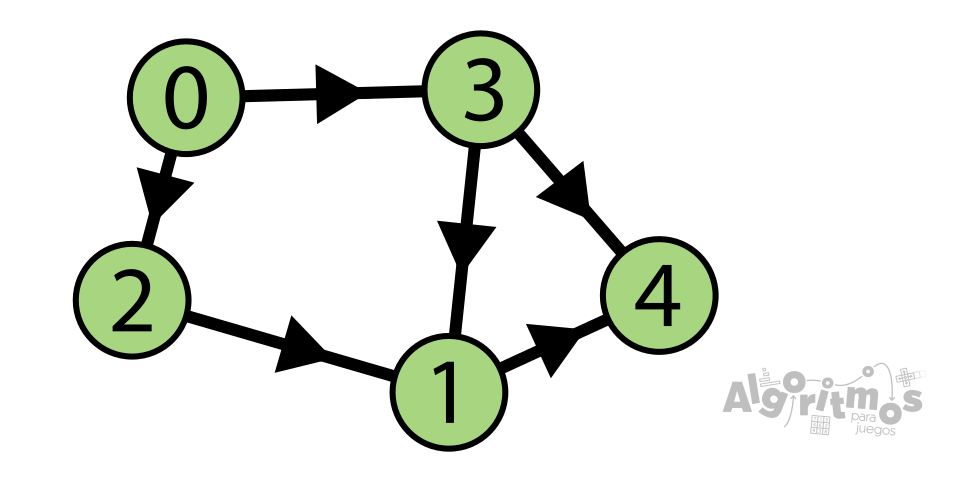
Hay dos posibles ordenaciones, ambas válidas: 0-2-3-1-4 y 0-3-2-1-4. A la hora de resolver problemas donde haya que realizar una ordenación, eligiremos siempre el que esté más ordenado topológicamente (el algoritmo que usaremos ya se encargará de esto).
Hay varias formas de implementar un algoritmo toposort. En la asignatura se estudia el algoritmo de Kahn.
Algoritmo de Kahn
xxxxxxxxxximport heapq
# Función principaldef toposort(g):
indegree = [0] * len(g) pq = []
# PASO 1: Calcular grados de entrada (indegrees) # de todos los nodos del grafo for u in range(len(g)): for v in g[u]: indegree[v] += 1
# PASO 2: Introducir a la cola de prioridad (pq) # los nodos con indegree 0 (sin dependencias)) for node in range(len(g)): if indegree[node] == 0: heapq.heappush(pq, node)
# PASO 3: Iterar por los nodos del pq e ir añadiendo # los vecinos, llevando un registro del orden. while pq: node = heapq.heappop(pq) for neighbor in g[node]: indegree[neighbor] -= 1 if indegree[neighbor] == 0: heapq.heappush(pq, neighbor)A diferencia de los algoritmos DFS y BFS, aquí hemos implementado todo el código usando un único método principal. En este caso la estructura de datos que se usa es una cola de prioridad (priority queue), implementada mediante el módulo heapq.
Los pasos que se siguen son:
Inicializamos la cola de prioridad
pqy una lista de indegrees. El indegree (o grado de entrada) de un nodo indica el número de aristas que llegan al mismo. Por ejemplo, si tres aristas apuntan a un nodo V, su grado de entrada es de 3.En el paso 1, calculamos los grados de entrada de todos los nodos del grafo, contando el número de entradas que tiene en la lista de adyacencias.
En el paso 2, introducimos en la cola de prioridad los nodos con grado de entrada 0, es decir, que no dependan de ningún otro nodo. Esto implicará que serán los primeros en nuestra lista de ordenación.
En el paso 3, mientras siga habiendo nodos en la cola de prioridad, iremos añadiendo los nodos "hijo" de cada uno de los nodos que introducimos anteriormente, restando el grado de entrada y añadiéndolos cuando llegan a cero.
Applet interactivo: ¿Aún tienes dudas? ¿Quieres ver cómo se van añadiendo los nodos a la cola de forma dinámica? ¡Prueba el applet interactivo de la ordenación topológica!